스레드와 멀티스레딩 (명품_운영체제 Ch 04)
태스크(task) : 컴퓨터가 처리하고자 하는 일의 단위 멀티태스킹(multi-tasking) : 여러 태스크(응용프로그램)를 동시에 실행하거나 한 응용프로그램 내에서 여러 태스크를 동시에 실행시키는 기법
프로세스를 실행 단위로 하는 멀티태스킹의 문제점
- 프로세스 생성의 큰 오버헤드
- 모두 독립적인 메모리 공간을 가지기 때문에 생성 과정이 오래 걸린다
- 메모리 할당, 부모 프로세스 메모리 복사, PCB 생성, 매핑 테이블 구성 등의 작업 진행
- 모두 독립적인 메모리 공간을 가지기 때문에 생성 과정이 오래 걸린다
- 컨텍스트 스위칭의 큰 오버헤드
- 시간적 공간적 소모가 큼
- 매핑 테이블 교체, 컨텍스트 정보 저장 및 새로운 정보 이동, 기타 데이터 무력화 및 적재 등등
- 시간적 공간적 소모가 큼
- 통신의 어려움
- 독립된 공간에서 실행되어 다른 프로세스의 메모리에 접근할 수 없다
- 통신하기 위해 공유 메모리, 신호, 파이프, 파일, 소켓, 메시지 큐, 세마포, 메모리맵파일 등의 기법 사용
- 독립된 공간에서 실행되어 다른 프로세스의 메모리에 접근할 수 없다
스레드
프로세스보다 작은 크기의 실행 단위(가벼운 프로세스, LWP 라고도 부른다) 현대 운영체제는 대부분 멀티스레드 운영체제이다
- 주소공간을 가진 실체(프로세스의 주소공간을 나누어 사용)로서, 운영체제에 의해 제어됨
- 스레드마다
TCB 구조체를 두고 프로세스 처럼 관리됨- 운영체제 입장에선 TCB 구조체가 스레드의 실체임
- 프로세스는 여러 스레드를 가진
컨테이너개념으로 수정됨- 스레드는 반드시 프로세스 안에 존재한다
-
같은 프로세스 내의 스레드들은 자원(영역)을 공유한다(코드, 데이터, 힙)(스택은 개별적으로 할당)
- 프로세스를 생성할 떄, 커널은 자동으로 프로세스 내에 1개의 스레드를 생성한다
이것을메인 스레드(main thread)라고 한다- 프로세스의 실행은 곧 메인 스레드의 실행이다
- 메인 스레드가 다른 스레드를 생성하고, 그 스레드가 또 다른 스레드를 생성한다
PCB vs TCB
- 스레드 스케줄링을 할 때, 프로세스 스케줄링이 선행될 필요가 없다
- PCB에는 프로세스 내에 있는 스레드에게 공통적으로 적용되는 정보들, TCB에는 각각의 스레드의 고유 정보들을 담는다
스레드 생성 과정
스레드의 실행할 작업은 함수로 작성된다 (main() 함수는 메인 스레드가 실행할 작업)
- 스레드가 실행할 작업 -> 함수
- 스레드가 사용할 데이터 -> 전역 변수, 함수 내 지역 변수
- 스레도르 만든 함수가 종료되면 스레드가 종료된다
- 스레드가 종료되면 관련 정보를 모두 제거한다
- 프로세스 내의 모든 스레드가 종료되면 프로세스가 종료된다
- 프로세스가 종료되면 관련 정보를 모두 제거한다
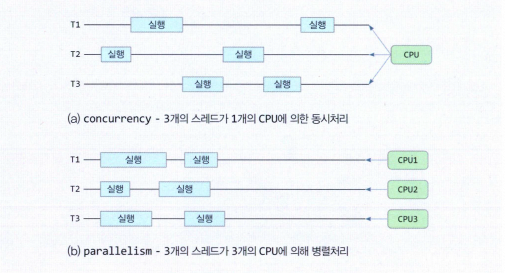
멀티스레딩
멀티스레딩은 다수의 스레드를 동시에 실행시키는 기법으로 두 가지의 경우로 구분된다
- 동시성(concurrency)
- 1개의 CPU(정확히는 1개의 코어)로 2개 이상의 스레드(혹은 프로세스)를 시간을 나눠 실행하는 것
- (a) 그림과 같이 입출력 요청, 타임 슬라이스 초과등의 상황에 컨텍스트 스위칭을 통해 다른 스레드에게 CPU를 할당하는 방식
- 여러 스레드를 쪼개서 섞어 실행하는 느낌
- 병렬성(parallelism)
- 2개 이상의 스레드가 서로 다른 CPU(코어)에서 동시에 실행되는 것
- (b) 그림과 같이 각각의 CPU에서 스레드들이 실행되는 병렬처리 되는 것
- 중간의 공백은 입출력 등의 CPU 유휴 상태
스레드 주소 공간
스레드의 주소 공간은 프로세스의 주소 공간에 형성된다
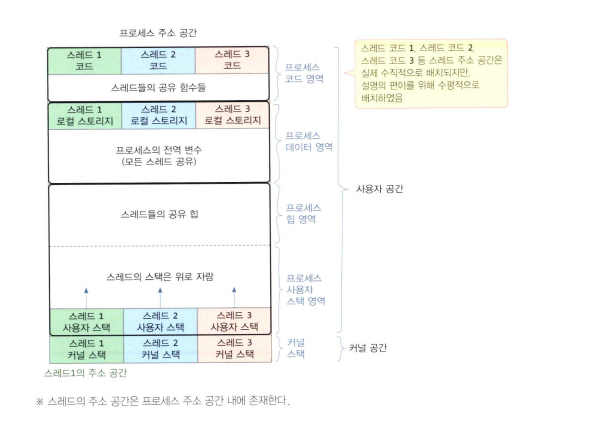
- 공유 공간
- 프로세스의 코드, 데이터(로컬 스토리지 제외), 힙 영역
- 사적 공간
- 스레드 스택, 스레드 로컬 스토리지
영역 구분
- 스레드 코드 영역
- 프로세스의 코드 영역내에 형성됨
- 프로세스의 함수 = 스레드의 코드
- 다른 스레드와 자원을 공유한다
- 스레드 데이터 영역
- 프로세스의 데이터 영역 내에 형성됨
- 스레드 로컬 스토리지(TLS)에 자신만의 변수를 선언한다(공유 X)
- 그 외에 전역변수들은 공유한다
- 스레드 힙 영역
- 스레드가 요청하는 동적 메모리 할당은 프로세스의 힙에서 할당되는 것이다
- 주소만 알면 다른 스레드가 접근할 수 있어 데이터를 주고받는 통신 장소로 사용된다
- 스레드 스택 영역
- 프로세스의 스택을 스레드 스택으로 할당
- 스레드의 사적 공간으로 함수 정보를 독립적으로 저장
스레드 상태와 운용
- 프로세스의 상태, 운용과 거의 같다고 보면 됨
- 종료 과정만 다름
- 스레드 스스로 종료하거나 프로세스가 종료되거나
- 스레드에도 부모-자식 관계가 존재하지만 종료에 있어서 영향을 주지 않음
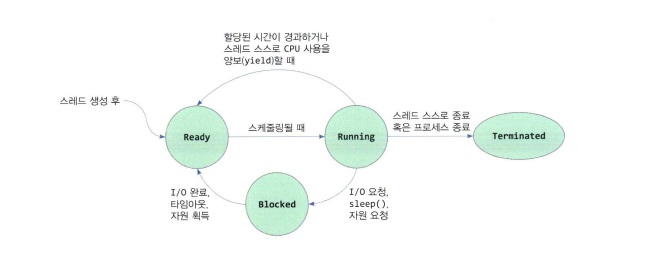
스레드 생성과 종료
- 생성 과정
- TCB 구조체 생성
-> 고유 ID 부여
-> 스레드가 실행할 함수 주소를 TCB의 PC에 기록
-> 스택을 할당하여 함수 주소를 TCB의 SP에 저장
-> 스레드 상태를 Ready로 하고 준비 리스트에 삽입
-> TCB를 PCB와 다른 TCB에 연결
- TCB 구조체 생성
- 종료
- 프로세스 종료 시 모든 스레드가 종료된다
- 프로세스가 종료되는 상황
1. main 스레드의 종료
2. 특정 스레드의 exit() 호출
3. 모든 스레드의 종료
- 프로세스가 종료되는 상황
- 스레드만 종료하려면 pthread_exit() 호출
- main 스레드도 해당 함수 사용 시 프로세스 종료 없이 종료 가능
- 부모 스레드가 종료되어도 자식 스레드가 종료되는 것은 아니다
- 프로세스 종료 시 모든 스레드가 종료된다
스레드 컨텍스트와 제어 블록(TCB)
- 스레드 컨텍스트
- 스레드가 현재 실행중인 일체의 상황
- CPU가 스레드를 실행하고 있을 때 CPU 레지스터들의 값을 의미한다
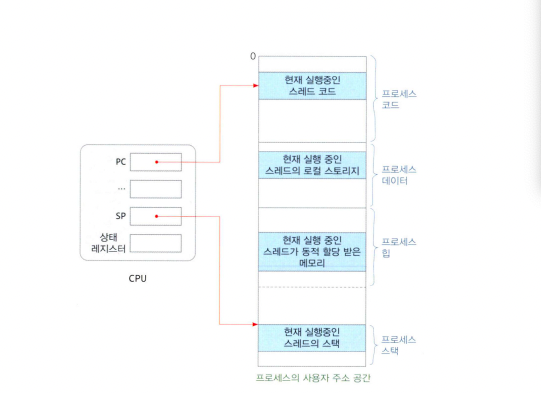
- 스레드 제어 블록(TCB, Thread Control Block) 구성요소
- tid : 스레드 ID
- state : 스레드 상태 정보(Running, Ready 등)
- PC : CPU의 PC 레지스터 값
- SP : CPU의 SP 레지스터 값
- 기타 레지스터 값
- 우선순위 : 스케줄링 우선순위
- CPU 사용 시간 : 생성 이후 CPU를 사용한 시간
- PCB 주소 : 스레드가 속한 프로세스의 PCB 주소
- 다른 TCB 주소 : 같은 프로세스 내의 다른 TCB와 연결하기 위함
- 블록 리스트 / 준비 리스트 등
스레드 컨텍스트 스위칭
현재 CPU가 실행 중인 스레드를 중단시키고 새 스레드를 실행시키는 과정
- 스위칭이 발생하는 경우
- 자발적인 양보
yield() 시스템 호출을 통한 직접적인 양보 또는 sleep(), wait() 등의 시스템 호출을 불러 다른 스레드로 컨텍스트 스위칭 되는 경우 - I/O 작업 요청으로 인한 블록 상태
- 타임 슬라이스 소진
- I/O 장치로부터 인터럽트가 걸린 경우
- 자발적인 양보
컨텍스트 스위칭의 오버헤드
스위칭에 걸리는 시간이 크면 처리율이 떨어진다
동일한 프로세스의 다른 스레드로 스위칭하는 경우에 발생하는 시간
- 컨텍스트 저장 및 복귀 시간
- TCB 리스트 조작 시간
- 캐시 플러시 및 채우기 시간
다른 프로세스의 스레드로 스위칭하는 경우에 발생하는 시간
- 위의 3가지 시간
- 메모리 관련 오버헤드
- 추가적인 캐시 오버헤드
감소 방법
- 사용자 레벨 스레드 활용
- 커널을 통해 관리되는 것이 아닌 자체적으로 스케줄링
- 하이퍼스레딩(hyper-threading)
- CPU 내부에 있는 코어 하나마다 2개의 레지스터 셋을 두어 2개의 스레드를 스위칭하며 실행
- 컨텍스트 스위칭에 발생하는 레지스터 값 저장에 대한 시간이 줄어든다
커널 레벨 스레드와 사용자 레벨 스레드
- 커널 레벨 스레드
- 커널에 의해 스케줄링되는 스레드
- 시스템 호출을 통해서만 생성, 관리, 활용된다
- ex) main 스레드
- 사용자 레벨 스레드
- 스레드 라이브러리에 의해 스케줄링되는 스레드
- 사용자 공간에서 생성, 관리, 스케줄된다 (커널에 전혀 알려지지 않는다)
- 스레드 라이브러리 함수 호출을 통해 생성하며, 모든 스레드 작업이 사용자 공간에서 이루어진다
- 순수 커널 레벨 스레드
- 부팅할 때부터 커널 공간에서 실행되도록 작성된 커널 레벨 스레드
- 커널을 돕는 목적으로 만들어짐
- ex) USB 인식 및 처리, 마우스 핸들링 등등
사용자 레벨 스레드 매핑
사용자 레벨 스레드도 결국에는 커널에 의해 스케줄링 되어야 실행된다 커널은 커널 레벨 스레드밖에 모르기에 변환을 위한 매핑(mapping)이 필요하다
- N:1 매핑
- 프로세스에 속한 모든 사용자 레벨 스레드의 1개의 커널 레벨 스레드로 매핑
- 장점
사용자 레벨 스레드는 커널에 진입하는 과정 없이 작업이 사용자 공간에서 이루어져서 프로그램 실행 속도가 빠르다 - 단점
사용자 스레드 중 하나에게만 CPU 코어가 할당되어 병렬성을 잃는다
사용자 스레드 중 하나가 블록 상태가 되면 다른 스레드 모두 실행 불가하여 프로그램이 중단된다
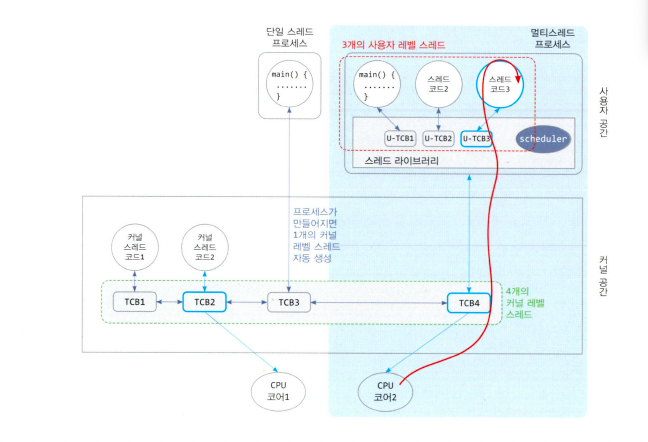
- 1:1 매핑
- 사용자 레벨 스레드 하나당 TCB(1개의 커널 레벨 스레드) 하나를 연계시킴
- 커널이 스케줄링을 통해 TCB 선택 시, 사용자 레벨 스레드 코드를 실행
- 대부분의 운영체제에서 사용한다
- 장점
단순하여 구현이 쉽다
서로 각자의 CPU 코어에서 실행되어 높은 병렬성을 가진다
같은 이유로 블록 상태가 되어도, 다른 스레드에게 영향을 주지 않는다 - 단점
사용자 레벨 스레드만큼 커널 레벨 스레드가 생기므로 스케줄링 시간 및 비용의 부담이 크다
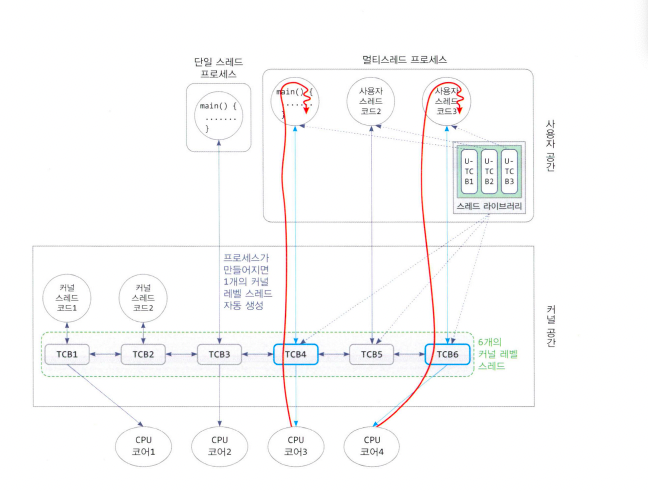
- N:M 매핑
- 사용자 레벨 스레드 중의 N개를 M개의 커널 레벨 스레드에 연계시키는 방법
- N:1, 1:1 매핑의 단점을 보완한다
- 장점
1:1 매핑에 비해 커널 레벨 스레드 개수가 적어 부담이 줄어듬 - 단점
매핑 및 스케줄링 과정이 복잡하여 거의 쓰지 않는다
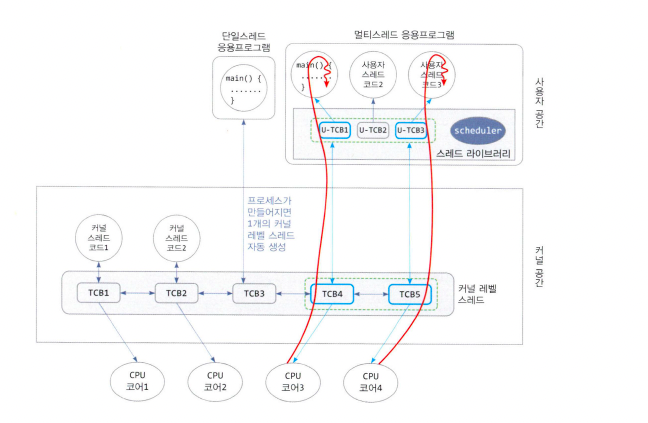
멀티스레딩의 장점과 주의할 점
장점
- 높은 실행 성능
- 사용자에 대한 우수한 응답성
- 서버 프로그램의 우수한 응답성
- 시스템 자원 사용의 효율성
- 응용프로그램 구조의 단순화
- 작성하기 쉽고 효율적인 통신
주의할 점
- 프로세스에 여러 개의 스레드가 있을 때, 한 스레드가 fork()를 통해 자식 프로세스를 생성하는 경우
- 생성된 자식 프로세스의 main 스레드는 fork()를 호출한 스레드만 만들고 나머지는 종료시킨다
- 결국 main 스레드만 유일하게 실행됨
- 부모 프로세스에 영향을 주진 않는다
- 위와 같은 조건에 exec()를 실행한 경우
- 모든 스레드를 종료시키고 프로세스 주소 공간에 새로운 응용프로그램을 적재한다
- 스레드 사이의 동기화 문제
- 공유 데이터에 동시 접근 시 데이터 훼손의 위험이 있다
댓글남기기